

Обзор подготовлен
При поддержке

Как правильно построить проект по внедрению DLP системы?
Главное при инициализации DLP-проекта - определить заранее, до начала не только проекта, но и до выбора технологии, какие критерии успешности будут предъявляться к DLP-системе. Иначе может получиться так, что хорошая технология не удовлетворила заказчика из-за того, что он не сможет ее использовать по предустановленным производителем сценариям.
Специфика проектов в области защиты информации от утечек (DLP) такова, что правильное планирование действий зависит не только от архитектуры информационной системы компании и технологического решения. Кроме определения объекта защиты и построения модели нарушителя, необходимо четко понимать цель проекта и критерии ее достижения, а также оценить необходимые ресурсы. Казалось бы, эти действия - классика, однако акценты в DPL-проектах расставляются несколько иначе.
Большинство технологий, представленных на рынке, требуют вовлечения компании заказчика в проект, той или иной реструктуризации системы обработки информации. Иногда для этого нужны не только деньги, но и добрая воля руководства, а также вовлечение в процесс внедрения всех пользователей информационной системы. В этом смысле DLP-проект очень похож на внедрение системы документооборота.
Выделить объекты защиты непросто
Даже разбуженный ночью сотрудник службы информационной безопасности отчеканит: "объект защиты – конфиденциальная информация, коммерческая тайна, персональные данные, банковская, государственная тайна и другая информация, охраняемая законами". Но для определения электронного объекта защиты такой информации недостаточно. Опыт внедрения большинства DLP-проектов показывает: максимум, что существует в компании на эту тему в начале проекта – это "перечень сведений…", составляющих конфиденциальную информацию. Однако для определения объекта защиты этого недостаточно.
DLP-системы могут защищать четыре типа объектов: документы, значимые цитаты из документов, формы (шаблоны) и лингвистические образцы документов. Если компания внедряет систему, которая может защищать только один тип объектов, ей нужно будет "конвертировать" "перечень" в этот тип объектов. Большинство систем, представленных на рынке, умеют защищать все упомянутые объекты, поэтому будем считать, что у заказчика для каждого типа защищаемой информации есть выбор, к какому объекту удобнее его приводить. Проекция "перечня" на всю электронную информацию в ИС компании и является самой трудной частью любого DLP-проекта.
Защита документов может проходить на разных уровнях. Защитить статический документ от утечки в неизменном виде достаточно просто. Для этого используются два основных способа – защищенный формат и статистические методы.
При использовании защищенного формата вводится реестр (каталог) всех защищаемых документов (что само по себе нетривиальная задача). После чего документы получают в этом реестре, во-первых, атрибут (метку), указывающий на то, что они защищены. А, во-вторых, защищенный (возможно, зашифрованный) формат, чтобы злоумышленник не смог вынести информацию из защищенного документа в незащищенный.
Типовая схема и логика работы DLP-системы
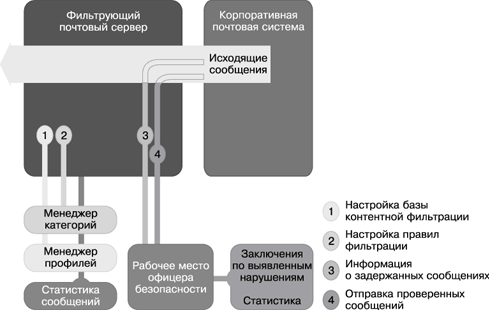
Источник: InfoWatch, 2008
В случае со статистическими методами с документов снимается некоторый отпечаток (контрольная сумма), которая используется затем для определения идентичности защищаемого документа его копии.
Все документы, подлежащие защите, складываются в одну папку. DLP-система отрабатывает процесс защиты документов или снятия с них отпечатков. Через некоторое время все документы в этой папке становятся конфиденциальными, и DLP-система берет их под свою защиту. Повторюсь, что это сильное упрощение, и в реальности можно указать системе местонахождение и/или атрибутный признак документа, но суть остается неизменной.
Пользователь в этом случае должен четко понимать, что если документ не попал в эту "папку", то обвинять DLP-систему в утечке такого документа бессмысленно – она все равно не сможет их защитить. Также нужно озаботиться тем, кто будет удалять документы и образцы из базы защищаемых элементов – бизнес требует такой функциональности. Например, спецификация нового продукта до его выхода является строго конфиденциальной, а после его выхода на рынок – общедоступной. Также обстоит дело с решениями совета директоров, маркетинговыми программами и т.д.
"Значимые цитаты" требуют внимания к себе
Защитой документов DLP-проект обычно не ограничивается, хотя некоторые компании считают, что для начала этого достаточно. С точки зрения администрирования все видится точно так же – документы в "папке" приобретают дополнительную защиту, не только от похищения целиком, но и от похищения значимой цитаты из них.
Значимой цитатой обычно называются части документа, которые сами по себе содержат конфиденциальную информацию. Некоторые DLP–системы не различают значимые и просто цитаты, защищая всю информацию, содержащуюся в документе. Понятно, что вынесенное за пределы документа слово, заведомо не содержащее конфиденциальную информацию, например - предлог, не представляет опасности. А система лишь будет тратить ресурсы на защиту от несуществующей угрозы. Однако грань между значимой и незначимой цитатой технически сложно определима, поэтому многие производители считают нужным перестраховаться.
Самое простое решение – просто запретить цитирование документа. Для этого разные производители используют либо формат, из которого ничего нельзя скопировать, либо специальные агенты на рабочих станциях. Последние или запрещают копирование документа и сохранение цитат из него, или присваивают копиям и документам с цитатами из секретного документа тот же гриф секретности.
Статистические решения не привязываются к документу, а контролируют выход за пределы информационной системы самих цитат, снимая отпечатки с исходящих документов и сравнивая их с образцами. Для этого с защищаемого документа снимаются отпечатки не только целиком содержания, но и всех возможных значимых цитат из него. От этого отпечаток сильно "тяжелеет", иногда составляя десятки процентов от оригинала. Несмотря на этот недостаток статистических решений, они удобны тем, что сильно разгружают рабочие станции, не требуя защищенных форматов и агентов на рабочих станциях.
Защита документов и значимых цитат из них перекладывает на администратора системы работу по созданию реестра защищаемых документов и поддержание его актуальности. Очень важным аспектом защиты на уровне документов является on-line обработка входящих и вновь создаваемых документов и защита тех из них, которые являются конфиденциальными.
Часто, ввиду ограниченности ресурсов служб ИБ, правом отнесения документа к разряду конфиденциальных наделяется автор или получатель документа. Соответственно, это делает бесполезным внедрение всей системы, нацеленной на защиту от внутреннего нарушителя, – ведь именно автор или получатель может оказаться злоумышленником или халатным пользователем.
Зачастую для удовлетворения требований регуляторов нужно защищать не документы, а конкретную информацию – данные пластиковых карт (пользователь, номер, срок действия) или персональные данные (номер телефона, адрес, номера идентифицирующих документов).
В этом случае упомянутые выше технологии не помогают – нельзя знать наперед все данные. Поэтому существующие DLP-системы используют технологии, которые определяют чувствительную информацию не по образцу, а по структуре (шаблону). В этом случае важно правильно настроить систему на те шаблоны, которые предстоит защищать.
Универсальность лингвистическая защиты имеет обратную сторону
Самыми распространенными на сегодняшний день являются системы, основывающиеся на лингвистическом анализе текста. Это обусловлено тем, что, при всех известных их недостатках такие системы требуют минимального вмешательства в систему хранения информации и обращения с ней. Каждый исходящий документ получает набор текстовых индексов и автоматически относится к некоторым группам категорий, как это делается в системах индексации и категоризации в сети интернет.
В этих случаях ресурсов отдела информационной безопасности вполне хватает, чтобы реализовать сценарий действий для каждой категории контента. Не нужны процедуры контроля процессов доступа к документу и цитированию из него. Если текст содержит конфиденциальные данные, система поймет это сама, независимо, был документ в реестре защищаемых или нет. Не нужно анализировать каждый новый документ в системе на наличие конфиденциальной информации – система найдет его сама, если по лингвистическим признакам он будет конфиденциальным.
Обратная сторона такой универсальности и простоты – трудоемкость создания лингвистического отпечатка системы (в России часто используется термин БКФ – база контентной фильтрации). Чаще всего он делается вручную с привлечением профессионального лингвиста.
Хотя уже сейчас существуют лингвистические процессоры, которые позволяют создавать лингвистический отпечаток конфиденциальной информации в системе по набору образцов, они пока не очень распространены. В частности, богатый опыт создания баз контентной фильтрации под каждого заказчика имеет компания-разработчик DLP-систем InfoWatch.
Однако неоспоримый плюс системы – возможность делать такую базу постепенно, начиная с заведомо конфиденциальных словоформ и двигаясь дальше, анализируя ложные срабатывания и используя навыки системы самообучения.
Возвращаясь к состоянию компаний при "нулевом цикле" проектирования DLP-системы, можно сказать, что только лингвистические методы позволяют начать работу по защите информации при наличии только "Перечня конфиденциальной информации".
Что нужно пользователю перед стартом DLP-проекта? Во-первых, необходимо оценить свои ресурсы и понять, что пользователь сможет предоставить DLP-системе в качестве защиты – образцы документов, сами документы или только "перечень". Далее, определить, кто и каким образом будет относить к защищаемым новые и входящие документы, а также удалять документы из реестра защищаемых.
Затем нужно решить, какие силы службы защиты информации могут быть потрачены на синхронизацию аналитической части DLP-системы с информационным полем компании.
После этого уже можно и выбирать соответствующую технологию защиты информации, а также использующую ее DLP-систему. Именно правильный баланс защищенности информации, вовлеченности заказчика в проект и количества ресурсов, затраченных на проект, приводит к удовлетворенности заказчика.
Рустэм Хайретдинов


Денис Зенкин:
Слияния и поглощения на DLP-рынке открывают широкие возможности для новых игроков
Рынок решений для защиты конфиденциальности данных развивается невиданными темпами. Термин "инсайдер" стал настолько модным, что редкий разработчик продуктов по ИТ-безопасности не предлагает защиту от этой угрозы. Что такое DLP? Как разобраться в многочисленных продавцах ходового товара и выбрать то, что реально нужно? Каковы тенденции развития современного DLP-рынка? В чем особенности стандартных подходов к защите данных от утечки? Об этом в интервью CNews рассказал Денис Зенкин, директор по маркетингу компании Perimetrix.
CNews: В чем состоит стандартизация методов защиты конфиденциальных данных?
Для построения действительно эффективной защиты нужно отделить зерна от плевел, понять, какие данные являются конфиденциальными, подлежат контролю и внедрить режим их защиты. Это нелегкая задача, но без нее любые инвестиции в DLP-решения – пустая трата денег и "технологии для галочки". Невозможно надежно защитить объект, не зная его "в лицо". Это подтверждается и исследованием Gartner – максимальная эффективность в отсутствие классификации не превышает 80%. Несмотря на простоту внедрения, увлечение канальными решениями вводит заказчиков в заблуждение ложной защищенности.